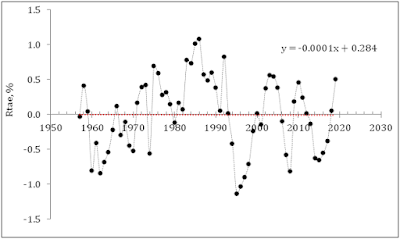
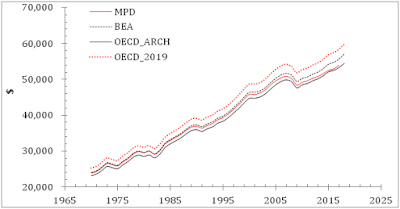
According to the
gap version of Okun’s law, there exists a negative relation between the output
gap, (Yp-Y)/Yp,
where Yp is potential
output at full employment and Y is
actual output, and the deviation of the actual unemployment rate, u, from its natural rate, un. The overall GDP or output
includes the change in population as an extensive component which is not
necessary dependent on other macroeconomic variables. Econometrically, it is
mandatory to use macroeconomic variables of the same origin and dimension.
Therefore, we use real GDP per capita, G,
and rewrite Okun’s law in the following form:
du
= a + bdlnG (1)
where du is the change in the rate of
unemployment per unit time (say, 1 year); dlnG=dG/G is the relative change rate in real
GDP per capita, a and b are empirical coefficients. Okun’s law implies b<0.
The intuition behind Okun’s law is very simple. Everybody may feel that the rate of unemployment
is likely to rise when real economic growth is very low or negative. An economy
needs fewer employees to produce the same or smaller real GDP also because of labor
productivity growth.
When integrated between t0 and t,
equation (1) can be rewritten in the following form:
ut =
u0 + bln[Gt/G0] + a(t-t0) + c (2)
where ut is the rate of
unemployment at time t. The intercept
c≡0, as is clear for t=t0. Instead of using the continuous form (2), we
calculate a cumulative sum of the annual estimates of dlnG with appropriate initial
conditions. By definition, the cumulative sum of the observed du’s is the time series of the
unemployment rate, ut. Statistically,
the use of levels, i.e. u and G, instead of their differentials are
superior due to suppression of uncorrelated measurement errors.
We showed (Kitov, 2011) the necessity
of structural breaks in (1). Therefore, we introduced floating structural breaks in (2), which years have to be determined by the best fit. Thus,
relationship (2) should be split into N segments. The integral form of Okun’s
law should be also split into N time segments:
ut = u0 + b1ln[Gt/G0]
+ a1(t-t0), t<ts1
ut = us1 + b2ln[Gt/Gts1]
+ a2(t-ts1), ts2≥t ≥ts1…
ut = usN-1 + bNln[Gt/GtsN-1]
+ aN(t-tsN-1), tsN≥t ≥tsN-1 (3)
In 2011, we
started with the U.S. The LSQR method applied to the integral form of Okun’s
law (3) results in the following relationship:
dup =
-0.406dlnG + 1.113, 1979>t≥1951
dup =
-0.465dlnG + 0.866, 2010≥t≥1979 (4)
where dup is the predicted annual
increment in the rate of unemployment, dlnG
is the relative change rate in real GDP per capita per year. A structural
break around 1979 was found. It divides the whole 60-year interval into two
practically equal segments. Figure 1 displays the measured and predicted rate
of unemployment in the U.S. since 1951. The agreement between these curves is
excellent with a standard error of 0.55%. The average rate of unemployment for
the same period is 5.75% with a mean annual increment of 1.1%. This is a very accurate model of unemployment
with R2=0.89. Hence, our
model (the integral Okun’s law) explains 89% of the variability in the rate of
unemployment between 1951 and 2010 with the model residual most likely related
to measurement errors. Statistically,
there is not much room for any other variables to influence the rate of
unemployment, except they are affecting the real GDP per capita.

Figure
1. The observed and predicted rate of
unemployment in the USA between 1951 and 2010.
Our initial model worked well and its performance can be further validated by new
data. Almost ten years passed and now we have two excellent opportunities to
check the model: new readings for the previous years since 2010 and the
extremely deep fall in the real GDP per capita accompanied by the unprecedented
growth in the rate of unemployment in the USA, both induced by the COVID-19
pandemic. The latter is a dynamic effect of an exogenous and non-economic force.
This is the best test of the link between the real GDP per capita and the unemployment rate.
In our previous
post, we supposed that the years between 2010 and 2019
have to be used to estimate the regression coefficient after the 2010 break. This
structural break is related to the change in real GDP definition as one can see
in Figure 2 from our previous
post. In the upper
panel of Figure 2 we present the evolution of the cumulative inflation (the sum
of annual inflation rates) as defined by the CPI and dGDP between 1971 and 2020.
Both variables are normalized to their respective values in 1970. In the middle panel, the dGDP cumulative
inflation is multiplied by a factor of 1.26 after 1979. The deviation since
1979 might be induced by a break in the GDP time series according to the comprehensive
NIPA revision. After 2010, the CPI and dGDP curves still deviate, however. This
effect is observed in new data and is likely associated with another break in the
GDP time series. In the lower panel, we use a new coefficient of 0.8 in order
to fit the CPI and dGDP after 2010. The overall fit is good and the total
factor for this period is 0.8*1.26=1.00. It seems the old GDP definition is
used after 2010.



Figure 2. Upper
panel: The evolution of the cumulative inflation (the sum of annual inflation
rates) as defined by the CPI and dGDP between 1971 and 2020. Both variables are
normalized to their respective values in 1970. Middle panel: The dGDP cumulative inflation is
multiplied by a factor of 1.26 after 1979. This deviation is induced by a break
in the GDP time series according to the comprehensive NIPA revision). After
2010, the CPI and dGDP curves still deviate. This effect is observed in new
data and is likely associated with another break in GDP time series. Lower
panel: A new coefficient of 0.8 is used to fit the CPI and dGDP after 2010. The
fit is good and the total factor for this period is 0.8*1.26=1.00. It seems the
old GDP definition is used after 2010.
The main result
of our meticulous inspection of the CPI and dGDP deviation is the presence of
breaks in data (i.e. data is not compatible in time) due to major revisions to the
real GDP definition. Such a break was used in our version of Okun’s law for the
USA as described by equation (4). The 2010 break may extend equation (3) to three
different segments: 1951 to 1979, 1980 to 2010, and after 2010, with three different sets of coefficients. When the 1979-to-2010 set of coefficients is
applied to the data after 2010 one obtains the curve shown in Figure 3, which
does not match the measured rate of unemployment. Therefore, we apply the standard LSQR
procedure to estimate a new set of coefficients for the period after 2010. The preliminary analysis gives the following model:
dup =
-0.406dlnG + 1.122, 1979>t≥1951
dup =
-0.465dlnG + 0.899, 2010≥t≥1979
dup =
-0.260dlnG - 0.250,
t≥2010 (5)
Figure 4 illustrates the
model predictive power. In the upper panel, the measured rate of unemployment in the USA
between 1951 and 2019 is compared with the rate predicted by model (5) with the
real GDP per capita published by the BEA. The rate of unemployment is borrowed
from the BLS. In the middle panel, the model residual errors are presented with
a standard deviation of 0.49% and the mean unemployment rate of 5.8%. The lower panel depicts the linear regression of the measured and predicted time series
with Rsq.=0.89. Hence, the new set of coefficients provides an excellent match
between the measured and predicted values, i.e. the model linking the change in the unemployment rate and the change in real GDP per capita is validated by the
data between 2010 and 2019.
Figure 3.
When the 1979-to-2010 set of coefficients is applied to the data after 2010 the predicted curve does not match the measured one.
Figure 4. Upper panel: The measured
rate of unemployment in the USA between 1951 and 2019 and the rate predicted by
model (5) with the real GDP per capita published by the BEA. Middle panel: The
model residual. Lower panel: linear regression of the measured and predicted
time series. Rsq = 0.89.
The ultimate validation test would be the model prediction for 2020, when
the rate of unemployment changes by 10% per
quarter and the real GDP per capita falls by 35% in one quarter and then jumps
back by 30%. It will be our next step after we present the prediction obtained
using the MPD estimates of the real GDP per capita. Figure 5 shows that the MPD
gives a slightly better fit with Rsq=0.91. This is just marginal improvement
but it is important in terms of the methodology of statistical estimates with not
perfect data measurements. Finally, Figure 6 presents the rate of unemployment predicted
for the three quarters of 2020. The spike in the second quarter is extremely
accurately predicted with the model (5) estimated for the period between 2010
and in 2019. It is a good indicator that the model is still applicable and there
were no NIPA revisions.
Interestingly,
the third quarter demonstrates a large prediction error – 5.3% instead of the measured
value of 8.8%. The predicted unemployment rate is obtained with the real GDPpc
growth of 30% in the third quarter. The
first GDP estimates for the third quarter might be highly overestimated. If the
measured value of 8.8% is correct, the GDPpc growth has to be only 17% from the
previous quarter. We will follow the BEA
releases with updated GDP estimates as well
as the BLS releases with new estimates of the unemployment rate. The fourth quarter
and the whole of 2020 is the next challenge for our Okun’s law version.
In any case, one can use the
unemployment estimates for an accurate prediction of the GDP growth!
Figure 5. Same as in Figure 4 with
the MPD estimates of the real GDPpc.
Figure 6.
The rate of unemployment predicted for three quarters of 2020. The spike in the
second quarter is extremely accurately predicted with the model (5) for the
period after 2010. The third quarter demonstrates a large discrepancy, but the
first GDP estimates might be highly inaccurate.